

In order to accomplish natural language processing (NLP) tasks, big language models like PaLM, Chinchilla, and ChatGPT have made previously unthinkable leaps forward in the interpretation of guiding signals.
Instruction tuning, which involves fine-tuning language models on various NLP tasks organised with instructions, has been shown in the prior art to further improve language models’ ability to carry out an unknown task given an instruction. In this paper, they assess the methods and results of open-sourced instruction generalisation initiatives through a comparison of their respective fine-tuning procedures and strategies.
In this study, we dissect the various approaches to tuning the instructions, isolating their individual aspects for in-depth analysis and comparison. Using the term “Flan 2022 Collection,” they describe the data collection and methods that apply to the data and instruction tuning process that is concerned with the emergent and state-of-the-art outcomes of combining Flan 2022 with PaLM 540B, and they evaluate the critical methodological improvements in this collection.
The jobs and methods for adjusting classroom instruction found in the Flan 2022 Collection are the most extensive compilation of its kind. Better layout patterns and additional premium templates have been added.
Also Read: Google Introduces Its ChatGPT Rival
Common Ground for Text-to-Text Interaction


In contrast to BERT-style models, which can only output either a class label or a span of the input, we propose reframing all NLP tasks into a unified text-to-text-format where the input and output are always text strings using T5. Machine translation, document summarization, question answering, and classification are just some of the NLP tasks that can benefit from our text-to-text framework’s universal model, loss function, and hyperparameters (e.g., sentiment analysis). Training T5 to predict the string representation of a number rather than the number itself allows us to apply it to regression tasks.
Also Read: Google Could Soon Let Users Turn Their Android Phones into Webcams
Large Dataset Used for Pre-Training (C4)

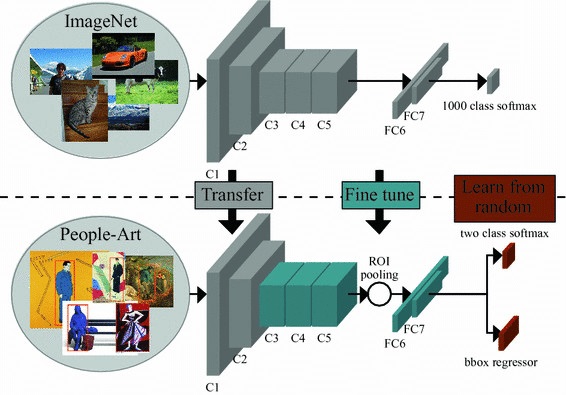
The unlabeled dataset used for pre-training is a crucial component of transfer learning. If one wants to accurately gauge the impact of increasing the amount of pre-training, a large, high-quality, diverse dataset is required. Currently available pre-training datasets fall short of satisfying all three of these requirements; for example, Wikipedian text is of high quality but uniform in style and relatively small for our purposes, while Common Crawl web scrapes are massive, highly diverse, but fairly low quality.

In order to meet these criteria, we constructed C4, a cleaned version of Common Crawl that is ten times larger than Wikipedia. When we were done, we had eliminated duplicates, discarded fragments, and cleaned up any offensive or distracting material. This filtering improved performance on downstream tasks, and the extra space let us train a larger model without risking overfitting. TensorFlow Datasets is where you can find C4.
Also Read: Google tries to reassure investors on AI progress as ChatGPT breathes down its neck
A Methodological Analysis of Transfer Learning

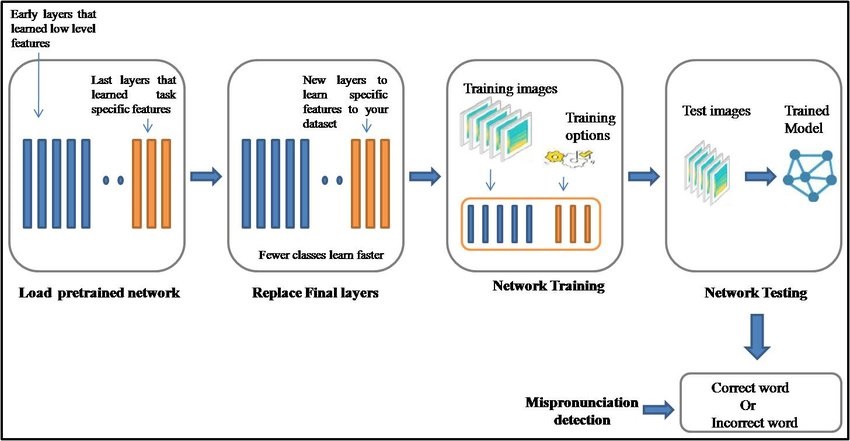
We conducted a comprehensive review of the many new ideas and methods introduced for NLP transfer learning over the past few years using the T5 text-to-text framework and the C4 pre-training dataset. Our paper contains the comprehensive results of our investigation, including our experiments with:
In terms of model architectures, we discovered that encoder-decoder models outperformed “decoder-only” language models; in terms of pre-training objectives, we confirmed that fill-in-the-blank-style denoising objectives (where the model is trained to recover missing words in the input) worked best and that the most important factor was the computational cost; and in terms of unlabeled datasets, we demonstrated that training on in-domain data can be beneficial, but that pre-training on.
Also Read: It Appears that Google Will Debut Their Chat Gpt Clone on February 8.
Automatically Creating Blank Form Text
Since GPT-2 and other large language models are trained to predict what words will come next after an input prompt, the generated text appears very natural and convincing. This has inspired many novel uses, such as the educational tool Talk To Transformer and the entertaining text-based game AI Dungeon. T5’s pre-training objective is more akin to a fill-in-the-blank task, where the model guesses at the whereabouts of missing words in a tainted text. Since the “blanks” can also appear at the end of the text, this goal represents a generalisation of the continuation task.
Using this goal in mind, we developed a new downstream task called sized fill-in-the-blank, in which the model is tasked with filling in a blank with a predetermined number of words. If we train the model with the input “I like to eat peanut butter and _4 sandwiches,” for instance, it will learn to fill in the blank with a string of words consisting of around 4.
Also Read: Google’s Experimental ChatGPT Rivals Include a Search Bot And a Tool Called ‘Apprentice Bard’
Conclusion
We look forward to seeing how other people incorporate our research results, code, and pre-trained models into their own projects. For more information, visit the Colab Notebook, and let us know how you’re putting it to use on Twitter.